

Ramon Eijkemans
Eikhart - Mad Scientist
Google Sheets scraper
I found this script to be particularly useful for monitoring of migrated elements across a large(r) number of URLs (conservative estimation: up to 1000 / 1500)
In Google Sheets you can use =IMPORTXML() with xpath expressions to return values from a HTML-page. We can greatly improve upon this! Because while the native function is pretty neat and relatively easy to use, it quickly becomes slow if you want to scrape a bit more than a few URLs and a few elements.
Also, xpath is not the easiest of declarations.
BUT
There is one huge advantage to Google Sheets when compared to other cloud based or desktop crawlers: it's way easier to refresh individual URLs, or a bunch of them. This is especially useful when dealing with a live migration!
Case: 1000 URLs #
Let's say I want to know the following from 1000 URLs:
-
-
url-stuff: status code (note:
=IMPORTXML()can’t even do this), robots, canonical -
-
meta: title, description
-
-
open graph: og:title, image, url, description
-
-
and the h1-tag value
These are 9 HTML-elements, for 1000 URLs. Instead of 9000 requests with =IMPORTXML(), we can do it in 1000 requests (where every request returns all 9 elements at once), making scraping with Google Sheets a lot faster!
Also, we will use something easier than xpath to select HTML elements: css selectors.
Let's get started.
Step 1: add Cheerio to your sheet #
Did you know you can load external libraries into Google Apps and so use their goodness? For this, I've used Cheerio, which basically mimics jQuery's element selection easyness.
-
-
In the Google Sheet you want to use this script with; go to
Extensions>Apps Script -
-
Now you’re in the In Apps Script interface. Go to
Librariesin the sidebar to the left, and click the+button -
-
Copypaste the following library ID:
1ReeQ6WO8kKNxoaA_O0XEQ589cIrRvEBA9qcWpNqdOP17i47u6N9M5Xh0 -
-
Click
Lookup, select the highest number from the list, and clickAdd
Congrats! Now you’ve added the scraping power of Cheerio to your Apps Script! This will enable you to use css selectors instead of xpath, which is way easier (thank me later).
Also, for those of you familiar with jQuery: it uses a familiar syntax for selecting stuff ;)
Step 2: copy paste this Apps Script #
We need to use a custom function in Google Apps Script for this. Don't worry: it's easy, because I've already written the code for you ;)
The only thing you need to do, is to copy the code and paste it into the Script Editor:
-
-
go to
Tools>Script Editor -
-
delete the
function myFunction() {}example code -
-
and replace it with the following code:
/**
* Scrapes various metadata from a given URL using Cheerio, a jQuery-style library.
* Extracts elements like title, meta tags, and headings, and returns them in an array.
*
* @param {string} url - The URL to be scraped.
* @return {Array} - An array containing the scraped data.
* @customfunction
*/
function scraper(url) {
var result = [];
var title, ogUrl, ogTitle, ogImage, ogDescription, description, h1, robots, canonical;
var options = {
'muteHttpExceptions': true,
'followRedirects': false,
};
try {
// Trim the URL to prevent errors
url = url.toString().trim();
var response = UrlFetchApp.fetch(url, options);
var responseCode = response.getResponseCode();
// Process only if response code is 200 (OK)
if (responseCode == 200) {
var html = response.getContentText();
var $ = Cheerio.load(html); // Cheerio library must be added to the project
// Extract various metadata from the HTML
robots = $('meta[name="robots"]').attr('content')?.trim() || '';
canonical = $("link[rel='canonical']").attr("href") || '';
title = $('title').text().trim() || '';
description = $('meta[name=description]').attr("content")?.trim() || '';
h1 = $('h1').text().trim() || '';
ogUrl = $('meta[property="og:url"]').attr('content')?.trim() || '';
ogTitle = $('meta[property="og:title"]').attr('content')?.trim() || '';
ogImage = $('meta[property="og:image"]').attr('content') || '';
ogDescription = $('meta[property="og:description"]').attr('content')?.trim() || '';
}
// Push the extracted metadata into the result array
result.push([responseCode, canonical, robots, title, description, h1, ogUrl, ogTitle, ogImage, ogDescription]);
} catch (error) {
// Push any errors encountered during the process
result.push(error.toString());
} finally {
// Return the result array
return result;
}
}
That's it. Now you can give this function a URL as parameter input, and it will return all 9 fields for you in one go. I'll show you how.
Step 3: use it #
So to use this function, simply pass a URL to it: =scraper(url). The output is 9 columns of data if the elements have value, and empty cells where the scraped elements have no value.
For sanity's sake, I usually add a check if the URL actually IS a valid URL:
=if(isurl(url);scraper(url);"non-valid url")Also, the script simply outputs the data it finds, but it doesn’t tell you actually what field it is from. So I’ve added everything you need to copypaste into your sheet in the table below:
Copypaste the table below and paste it right into your sheet:
| Status code | Canonical | Robots | Title | Meta description | H1 | og:url | og:title | og:image | og:description | |
|---|---|---|---|---|---|---|---|---|---|---|
| =if(isurl(url);scraper(url);"non-valid url") | ||||||||||
| That's it! Now you have your own realtime scraper. |
||||||||||
Some things to know #
The scraper refreshes, but only "kinda realtime(ish)"
By default, Google Sheets refreshes its data when the content of a cell (either a hardcoded text or the result of a formula) changes. You can however set a custom refresh interval when everything should change. For this, go to File > Settingsand choose between these options:
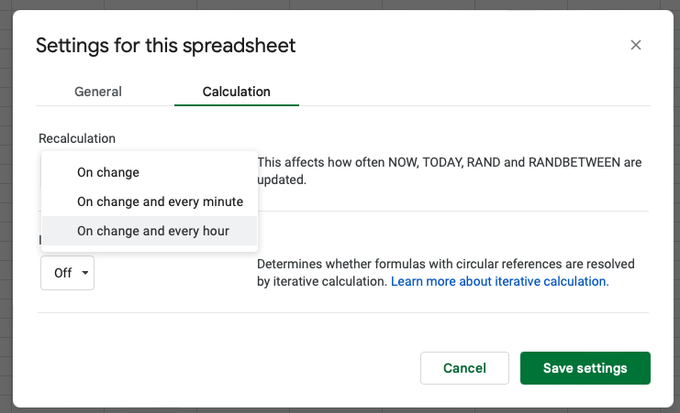
Default is onchange, but you can add an interval
Still not specific enough? What if you're changing redirects one by one, and you also want to check the redirected URLs one by one?
Easy!
Select the cell with the url in it and delete the contents. After that, undo (Ctrl-z (Windows) or cmd-z (macOS). Et voila: the scraper wil rerun immediately, but for only this cell.
What are the limits? #
You can’t use it on more than 1k / 1.5k URLs. You will get errors in the likes of Too many requests. That can’t be helped, sorry :(
What more can the scraper do? #
It can do a LOT more, YES! Just about anything you can think of.
Maybe i’ll elaborate a bit on it in a follow-up post, like adding some nice SEO-validations I’ve already added to my own internal versions, e.g. meta text length tests, cosine similarity and levenshtein distance between h1 and title, validity of phone numbers, or maybe even validation of analytics tags or red flag words.
The sky is the limit, really.
Ramon Eijkemans
Eikhart - Mad Scientist