
- A (very) small but useful exercise to get things going
- The main takeaway of this article: add structure to language
- Why this matters now, and should have mattered years ago already
- A quick word on what this framework is NOT: guaranteed citations
- This framework is built on mechanisms; not heuristics
- See it in action: the bio-rewriter
- My 5-point usefulness check, a.k.a. the Eikhart Language Utility Framework
- Combining it all
- A beginners' trap: oversimplifying
- This works both for LLMs AND Google
- What I'm still figuring out: How to combine this with emotional persuasion (a.k.a. "writing for humans')
- What I think the next step is: combining UX with utility-writing in microcopy
- Two things you can do right now
- References

Ramon Eijkemans
Eikhart - Mad Scientist
Utility-writing: add structure to language; not the other way around
How to write in such a way that machines that interpret language (LLMs, AI, chat, search engines, AI overviews, agents), can actually use whatever it is you want to say.
And no, the method is NOT technical. It's in writing.
A (very) small but useful exercise to get things going #
Before we dive in, I have a request. Can you do me a small favor? It's worth the effort. You'll understand this article better and it won't cost you much time. Just a little bit of honesty.
Yes?
Great, so here is my assignment for you: go to your own website and pick a high-value page. The one that answers the question most important to your business. Your main product, or one of them.
Then, pick a sentence from the middle. Not the intro, not the conclusion. The middle.
Copypaste that sentence into your note taker or somewhere else out of the context of your website. A new text doc in your editor, or just a quick draft in your email client. Doesn't matter much, just copypaste it somewhere else.
Now read that sentence in complete isolation. Pretend you're not you but someone else who reads it. A prospect, a reasonable surfer, someone anonymous. Then, from that viewpoint and in all honesty, answer these questions with either yes or no:
-
-
Can you reproduce, based on this content alone, what it's about? Not vaguely, but specifically: what thing, what product, what place?
-
-
Is that thing explicitly connected to something else, like a price, a name, a location, a feature?
-
-
And does it say something about the nature of that connection: is it good, bad, cheap, expensive, fast, slow?
If any of the answers is no, you've found the problem this article is about.
And you're not alone. I've been testing quite a lot, and it fails about 99% of the time. Even on well-written, well-ranking pages. So there's a 99% chance that applies to you too.
This isn't a ranking problem. It's a utility problem. The five techniques below show you what to fix; with plenty of practical examples, before and after.
One more thing before we dive in. Research on Google's Gemini system shows that the typical page gets about 380 words selected, regardless of how long the page is. Dan Petrovic tested this very article specifically and found that of 6,107 words (I've added a few in the meantime, but you get my point), only 948 (15.5%) were used to ground Gemini's response. The rest was invisible to Gemini for the query: "How to write to saitisfy both LLMs and humans?"
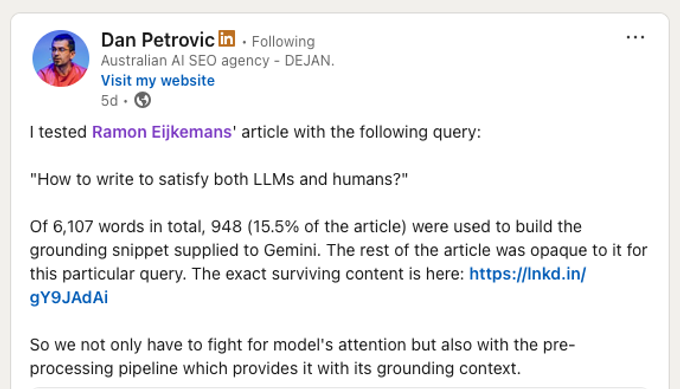
View Petrovic's analysis on LinkedIn. The analysis started from my post announcing this article.
This framework is evolving
One thing I should mention upfront: everything I describe here is evolving. I've been building and refining this analysis for over a year, and it changes every time I come across a useful patent, research paper, or even an interesting LinkedIn post. Every piece of literature I find gets evaluated on one question: can I use this to make the framework better?
The goal isn't science. It's application. What can I actually use, today, to measure and improve content utility? So treat this as a snapshot of where the thinking is now, not a final answer.
The main takeaway of this article: add structure to language #
SEOs know about structured data. We've spent a decade adding Schema.org, LD+JSON, and currently many are debating whether they should offer a markdown version of their bloated HTML to LLM bots.
Sigh.
While I definitely don't dispute the usefulness of structured data (quite the opposite! I love it, I'm a fanboy! Just to be clear on this), I think however we're forgetting what all this is about, what's actually easier to fix, and what is right there sitting in front of us.
Many treat structure as something you bolt onto text. A technical layer separate from the writing itself.
I'd say we don't need more of those technical layers, but should be using better structured language.
Let me explain what I mean.
Structured data translates human text into machine format. Structured language writes human text that is inherently machine-processable. One adds a layer. The other enriches the text itself. And then that text is useful food for content-eating machines to represent it correctly in different renderings, like chats, AI overviews, and even classical Google rankings.
Here's a concrete example. You could add Product schema to a page declaring the name is "Sony WH-1000XM5", the price is € 349, and availability is InStock. That helps a search engine understand the basics. But it can't carry why someone should buy it, how it compares, or under what conditions it's the right choice.
Natural language already has all the tools you need to achieve this though! You could for example write:
The Sony WH-1000XM5 noise-cancelling headphones reduce ambient noise by up to 30dB, weigh 250g (18% lighter than the XM4), and deliver 30 hours of battery life with ANC enabled. At €349, they're priced between the Apple AirPods Max (€549) and the Bose QuietComfort 45 (€279), with a noise cancellation benchmark score of 94/100 from RTINGS.com.
That sentence doesn't need a machine-readable overlay. It is machine-readable. It contains entities, relationships, conditions, comparisons, and specifics. A knowledge graph can extract triples from it1. A proposition-based system can decompose it into atomic claims2. And a human reads it just fine. No markup needed. And it carries far more than schema ever could: the comparison, the benchmark, the weight difference, the trade-offs.
Or take a completely different domain:
A property in Flanders with an EPC score above 400 kWh/m² qualifies for the Mijn VerbouwPremie subsidy of up to €4,750 for insulation work, on the condition that a certified contractor registered with the Flemish Energy Agency performs the work.
Same principle. Named entities (the property, the subsidy, the agency). Explicit relationships (qualifies for, on the condition that). Conditions preserved inline (EPC above 400, certified contractor). No markup required.
That's the whole idea. I call it utility-writing. And here is my working definition that you're welcome to quote:
Utility-writing is the practice of writing natural language that is inherently machine-processable: with named entities, explicit relationships, preserved conditions, and self-contained statements. The structure machines need is in the language itself; not in surrounding techniques.
Ramon Eijkemans
Everything else in this article is technique, with a lot of examples, for doing it well.
Why this matters now, and should have mattered years ago already #
There's a gap between what humans consider good content and what machines can actually use. Duane Forrester calls it the Utility Gap3. We read to understand. We tolerate warm-up paragraphs, appreciate narrative, scroll to find what matters. AI retrieval systems do something else entirely: they consume content in chunks and extract what they need to complete a task4.
A page can be great for humans and useless to a model. Indexed, credible, well-written, and still fail the moment a system tries to turn it into an answer5.
You should realize this isn't just about LLMs.
Google has been evaluating content at the passage level since 2021. The same qualities that make content useful to ChatGPT or Perplexity (clear passages, resolved references, explicit entity relationships, self-contained statements) are the same qualities that Google's passage ranking, AI Overviews, and featured snippets reward. I wrote about this in more detail in The Shared Mechanism: the underlying retrieval infrastructure is the same. You're not optimizing for different systems. You're optimizing for one evolving system that evaluates content at the passage level.
So when I say this should have mattered years ago: I mean it. The techniques in this article aren't "GEO tricks." They're better writing. And they've been rewarded by search engines since passage ranking went live.
A quick word on what this framework is NOT: guaranteed citations #
A lot of GEO advice right now is built on a correlation trap. The reasoning: brands that get cited in AI search tend to have pages with expert quotes, statistics, structured formatting, and topical depth. Therefore: add those things and you’ll get cited too.
Wrong!
That’s observing a trait of authoritative content and calling it a cause. High-authority pages happen to have those features. Adding the features doesn’t create the authority.
The techniques in this article are different. They’re not authority proxies. They’re structural requirements.
When a sentence contains an unresolved “it” or “this,” a proposition-based retrieval system mechanically fails to extract it as a self-contained claim. That’s not a correlation. It’s a documented failure mode in the Dense X Retrieval research. When your best content sits in the middle third of a long page, Google’s passage scoring assigns it a lower position bonus. That’s not a heuristic. It’s the heading vector and position scoring mechanism Kopp describes.
These things either work mechanically or they don’t. You can verify them. You can break them deliberately and observe the result.
So when someone asks “but how do you know these techniques cause citations rather than just correlate with them?” -> that’s the right question. And for most GEO advice out there, there’s no good answer. For the techniques here, there is: they map to observable retrieval mechanisms, not to the content traits of pages that were already winning.
This framework is built on mechanisms; not heuristics #
Olaf Kopp's work on LLM readability describes how this plays out in practice6. First, your page needs to pass source qualification: the traditional authority checks (E-E-A-T, domain trust, topical authority). That gate hasn't gone away. But once your page passes that gate, it's your individual chunks that compete. Your page gets in the door on authority. Your passages get cited on quality7.
The underlying mechanism is the same across systems: every retrieval architecture, whether it's Google's passage scorer, a RAG pipeline, or a proposition extractor, asks the same question about a chunk of text: how probable is it that this answers the query? The writing techniques that raise that probability work across all of them. Which is exactly the point!
This article focuses on your own content: making the language on your own pages more useful to machines. But the same principles carry over to how your brand shows up on other websites too, making sure your brand entity is connected to the right concepts in external sources. That's a different but equally necessary discipline, and beyond the scope of what I'm covering here.
Now, there's also a hard physical constraint that I think a lot of people underestimate.
Dan Petrovic's research on Google's Gemini system analyzed over 7,000 queries and found a grounding budget of roughly 1,900 words per query, split across sources8. The top source gets about 530 words. The fifth source? About 2709. For individual pages, the typical selection is around 380 words10.
It gets worse. Pages under 5,000 characters get about 66% of their content used. Pages over 20,000 characters? 12%11. Adding more content dilutes your coverage without increasing what gets selected12.
So yeah. Your best content needs to be dense, self-contained, and positioned where systems will find it. Not longer. Denser. Petrovic's own summary: density beats length13. Chunk completeness doesn't just determine whether a passage gets used. It determines three probabilities simultaneously: retrieval probability (does the chunk surface at all?), ranking probability (where does it land relative to other retrieved chunks?), and citation probability (does the generative system actually quote or attribute it?). A vague chunk doesn't simply fail to get cited. It gets mathematically outcompeted at each of those three gates. That's the underlying logic behind every writing technique in this article.
See it in action: the bio-rewriter #
Want to see this framework in action? I created a version that is optimized for refactoring conference and guestpost bio texts. You put in your bio, and it's optional to provide a little more details to make things sharper. Then the tool will analyze your text through my model, and return a machine-readable version, along with honest feedback if there are still things to modify to make it better. Use it to improve your E-E-A-T! :)
Check it out -> right here.
My 5-point usefulness check, a.k.a. the Eikhart Language Utility Framework #
I look at the utility of a text through five lenses. Together, they form my practical checklist for utility-writing. Let me walk you through what each one means in practice.
I'll use an extensive amount of examples because when I started looking at content this way, I learned that I learn best from concrete examples that actually show how it's done. So my aim is for you to find stuff in here that is useful for your own situation.
1. Put your best material where systems will find it #
Research on long-context models shows that information position matters. Claims near the beginning or end of content get used more reliably than claims buried in the middle14. Forrester's advice: If the most important part of your answer sits in the middle, promote it or repeat it in a tighter form near the beginning15.
This maps directly to web content. If your key conclusion sits halfway down a 3,000-word page, it will probably become functionally invisible.
Tech review
A Tweakers review of the Samsung Galaxy S25 Ultra runs 3,000 words. The conclusion sits in the last 10%:
The Galaxy S25 Ultra is the strongest Android choice for photography enthusiasts who prioritize zoom quality.
That's fine, end-of-page works.
But the critical comparison data? If that's buried in paragraph 18 of 25, it might never get extracted:
At 10x zoom, the S25 Ultra produces 38% sharper images than the Pixel 9 Pro in our lab measurements.
A hospital
A hospital page about hip replacement recovery runs 2,500 words. The most decision-critical bit sits in section 5 of 8:
Most patients can walk with assistance within 24 hours of anterior approach hip replacement, compared to 48-72 hours for posterior approach, but anterior approach carries a 2.1% higher risk of femoral fracture in patients over 75.
That's the Lost in the Middle zone. A patient asking "How soon can I walk after hip replacement?" might get an answer built from a competitor's page that put recovery timelines in the first paragraph. Not because your content was worse. Because it was in the wrong place.
SaaS
A product page leads with the company mission statement, brand values, and customer logos. The actual differentiation sits in the comparison section halfway down:
Unlike Salesforce, which requires a minimum 5-seat commitment at $25/user/month, HubSpot CRM offers a free plan for up to 5 users with contact management, deal tracking, and email integration.
That comparison data is exactly what an LLM needs to answer "What's a good free CRM for a small team?" But it's positioned where systems are least likely to find it.
The principle: within any piece of content there's a core block of ~500-600 words containing the most important claims. Know where that block is. Make sure it's in the first 20% or last 20%. Not the middle.
2. Give the system a reason to pick you over alternatives #
Getting retrieved isn't the same as getting cited. Research on product descriptions tested 15 different rewriting strategies, and after optimization, they all converged on the same features: alignment with user intent, comparison against alternatives, inclusion of external evidence like reviews, and preserved factual accuracy16.
Makes sense when you think about it.
Duane Forrester formalizes this into a formula: state what it is, who it's for, what job it does, and under what constraint it wins17. When your opening line is a slogan, the system has to infer what the product is actually for. And inference introduces uncertainty, uncertainty reduces selection18.
Let me show you what this looks like across industries, with some more example goodness :)
Real estate
A user asks an AI: "What are good neighborhoods in Antwerp for families under €400,000?". The following text might resonate on an emotional level, but it offers nothing useful:
Charming family home in a green, family-friendly neighborhood. This beautiful property offers everything you need for comfortable living.
Which neighborhood? What price? How many bedrooms? The system has to guess. It won't need to guess with this text though:
This three-bedroom terraced house in Berchem, Antwerp is listed at €385,000. Berchem offers direct tram access to Antwerp Central Station (12 minutes), three primary schools within 800 meters, and average property price growth of 4.2% per year over the past five years.
P.s. we're still writing for humans too though!
I think you should probably use *both* levels (emotion, utility) to speak to both humans and machines.
I'll get back to that later!
E-commerce
Marketing fluff text coming up:
Premium noise-cancelling headphones that deliver an incredible audio experience. Perfect for music lovers who demand the best.
But machines would prefer:
The Sony WH-1000XM5 noise-cancelling headphones reduce ambient noise by up to 30dB using dual-processor adaptive noise cancellation, weigh 250g (18% lighter than the XM4), and deliver 30 hours of battery life with ANC enabled. At $349, they're priced between the Apple AirPods Max ($549) and the Bose QuietComfort 45 ($279), with a noise cancellation benchmark score of 94/100 from RTINGS.com.
B2B/SaaS
Another amazing piece of text you've read nowhere else, anywhere, anytime (i'm joking of course, just so we're clear on this):
Our powerful analytics platform transforms your data into actionable insights, empowering your team to make better decisions faster.
And then the structured version:
Mixpanel tracks user behavior across web and mobile with event-based analytics, offering funnel analysis, retention cohorts, and A/B test reporting. The free plan supports up to 20 million events per month. For teams already using Amplitude, Mixpanel offers a migration tool that imports historical data and maps existing event taxonomies in under 48 hours.
Legal services
Our experienced attorneys provide comprehensive estate planning services tailored to your unique situation.
Versus:
Our estate planning practice at Sherman & Howard creates revocable living trusts, pour-over wills, and durable powers of attorney for Colorado residents. A standard estate plan for a married couple with assets under $5 million takes 3-4 weeks from initial consultation to signing, with fees ranging from $2,500 to $4,500 depending on complexity.
The difference isn't literary quality (as said before, I'll get back to that). It's utility. The first versions could describe any company anywhere. The second versions answer the actual questions a potential client (or the AI answering on their behalf) would have, and make it possible for machines to use it in their answers, with way less room for hallucination.
3. Make every sentence survive on its own #
This is where structured language gets concrete. The most common failure mode is coreference. Pronouns and vague references that break the moment a sentence gets extracted without its neighbors.
Research backs this up. Proposition-level retrieval (where systems decompose text into atomic, self-contained claims) outperforms passage and sentence-level retrieval19. And the main quality problem in automated proposition extraction? Failure to resolve coreferences. Exactly the "it" and "this" problem20.
Some concrete examples.
Tech review
Breaks when extracted:
It supports the latest Wi-Fi standard, which gives it a significant advantage over the previous model. Combined with the improvements mentioned above, this makes it our top recommendation in this price range.
What is "it"? Which Wi-Fi standard? Which previous model? What improvements?
This works though:
The ASUS ROG Ally X supports Wi-Fi 6E, providing up to 40% faster download speeds compared to the Wi-Fi 6 in the original ROG Ally. The Wi-Fi 6E support, combined with the doubled 24GB RAM and the 80Wh battery, makes the ROG Ally X the top-rated handheld gaming PC in the €600-800 price range on Tweakers.
Healthcare
This breaks too:
The medication has shown promising results in recent studies. Side effects are generally mild, though patients should discuss these with their doctor before starting treatment.
But this doesn't:
Ozempic (semaglutide 0.5-1mg weekly injection) reduced HbA1c levels by an average of 1.4 percentage points in the SUSTAIN-6 trial involving 3,297 patients with type 2 diabetes over 104 weeks. The most common side effects of semaglutide are nausea (15.8% of patients) and diarrhea (8.5%), which typically diminish after the first 4-8 weeks of treatment.
Finance
This breaks:
This account offers a competitive interest rate. With no monthly fees and easy access, it's a great choice for most savers.
And this works:
The Marcus by Goldman Sachs High-Yield Savings Account pays 4.40% APY with no minimum deposit, no monthly maintenance fees, and up to 6 free withdrawals per statement cycle. The rate is variable and may change after account opening.
Travel
This breaks:
The hotel is centrally located and offers excellent dining options. It's particularly popular during the peak season, so early booking is recommended.
But this works:
The Riad Fes in Fez, Morocco is located 200 meters from the Bab Boujloud gate in the medina, with a rooftop restaurant serving traditional Moroccan cuisine overlooking the old city. Room rates at Riad Fes range from $180/night in January-March to $340/night during peak season (April-May and September-October), and the property typically sells out 6-8 weeks in advance during Ramadan.
In summary, a nice reference table for you
Here are the most common extractability killers. They show up everywhere, in every industry:
| Pattern | Example | Problem |
|---|---|---|
| Unresolved pronoun (what?) | "It features a 120Hz display" | What device? |
| Vague demonstrative (what + what?) | "This gives it an advantage" | What gives what an advantage? |
| Context-dependent (which?) | "The above specs outperform the competition" | Which specs? Which competition? |
| Stripped conditions (when? how much?) | "The price has dropped significantly" | From what? To what? When? |
| Assumed knowledge (what? who?) | "The popular supplement helps with recovery" | Which supplement? Recovery from what? |
| Relative claim (how much? compared to what?) | "Our fastest-selling product" | How fast? Compared to what? Over what period? |
A simple rule of thumb: if a sentence doesn't survive the journalist's 5W test (who, what, when, where, why, and how), a machine can't do anything useful with it either.
4. State the relationships, not just the entities #
This is what most content strategies miss entirely. And I find this one the most interesting, because it's so counterintuitive.
It's not about which concepts you mention. It's about whether you explicitly connect them.
Graph-based retrieval systems build knowledge graphs from content by extracting (subject, predicate, object) triples from natural language. No predefined schema needed21. And it turns out: content with clear subject-verb-object structures gets extracted more accurately than bullet lists without verbs, tables without context, or fragments that require inference22.
Natural language with structure baked in beats both unstructured prose and stripped-down data points; for graph-based systems just as much as for passage-based ones.
Again some examples.
Real estate
A listing mentions all the right entities separately:
This property has an energy label D. Various renovation subsidies are available in Flanders. The estimated EPC score is 450 kWh/m². Insulation improvements can increase a property's value.
Four entities, zero relationships. A knowledge graph built from this has four disconnected nodes. Useless.
Now with relationships stated:
This property at Lange Leemstraat 45 in Antwerp currently has an EPC score of 450 kWh/m², corresponding to energy label D. Renovating to energy label B requires an estimated investment of €35,000-45,000 for roof insulation and window replacement. The Flemish 'Mijn VerbouwPremie' covers up to €4,750 of insulation costs for properties with an EPC score above 400 kWh/m². Installing a heat pump qualifies for an additional €4,000 subsidy, provided a certified installer performs the work.
Healthcare
Without relationships:
Metformin is a diabetes medication. Blood sugar monitoring is important. Exercise helps manage diabetes. A1C levels should be checked regularly.
And with:
Metformin (starting dose 500mg twice daily) typically reduces A1C levels by 1.0-1.5 percentage points over 12 weeks in patients with type 2 diabetes. The American Diabetes Association recommends combining metformin with 150 minutes of moderate aerobic exercise per week, which can reduce A1C by an additional 0.5-0.7 percentage points. Patients on metformin should have A1C tested every 3 months until stable, then every 6 months, with a target of below 7.0% for most adults.
Now the system can answer: "How much will metformin lower my A1C?" and "How often should I get my A1C tested on metformin?" directly. Because you stated the relationships, not just the entities.
Some more examples.
Finance
Without relationships:
Interest rates are important for mortgages. Your credit score matters. A larger down payment is beneficial. PMI is an additional cost.
And with:
A 30-year fixed mortgage rate at Wells Fargo averages 6.8% APR for borrowers with a credit score above 740 and a 20% down payment. Borrowers with credit scores between 680-739 typically pay 0.25-0.5% higher. Reducing the down payment from 20% to 10% adds private mortgage insurance (PMI) at 0.5-1% of the loan amount annually, which for a $400,000 home means an additional $2,000-4,000 per year until the loan-to-value ratio reaches 80%.
SaaS
Without:
We offer several pricing tiers. Enterprise features include SSO and advanced reporting. Our platform integrates with many tools. Custom contracts are available.
And with:
Datadog's Pro plan at $23/host/month includes APM with distributed tracing, 15-month metric retention, and up to 200 custom metrics per host. The Enterprise plan at $33/host/month adds SAML-based SSO, role-based access control, and live process monitoring. Teams running more than 500 hosts can negotiate custom pricing, which typically reduces per-host costs by 20-35% with annual commitment.
Multi-hop reasoning chains are where this gets interesting. "Is it worth buying a fixer-upper in Antwerp with a bad energy label?" requires a chain: energy label D means lower price → renovation costs X → subsidies offset Y → renovated properties appreciate Z%. If any link is missing, the chain breaks23.
The same multi-hop logic applies everywhere. "Should I refinance my mortgage?" needs: current rate → new available rate → closing costs → break-even timeline → remaining term impact. "Which cloud provider is cheapest for my workload?" needs: workload specs → pricing per unit → committed use discounts → egress costs → total cost comparison. Each link must be explicitly stated. Otherwise the system can't build the answer, and it'll use someone else's content instead.
5. Include at least one sentence an LLM could directly quote #
Last one. And maybe the simplest test.
Does your content contain a single passage that an AI system would confidently drop into a response? Forrester calls these "anchorable statements": sentences that look like stable claims with clear definitions, explicit constraints, and direct cause-and-effect phrasing24.
E-commerce
Not citeable:
This is a great coffee maker that produces excellent results and is very popular with customers.
And in contrast, citable:
The Breville Barista Express produces espresso at 9 bars of pressure with a built-in conical burr grinder, and is rated 4.6/5 across 12,000+ reviews on Amazon, making it the highest-rated semi-automatic espresso machine under $700.
Healthcare
Not citeable:
Recovery times vary depending on the individual and the procedure performed.
Citable:
Patients undergoing arthroscopic ACL reconstruction using a patellar tendon autograft can typically return to desk work within 1-2 weeks, light exercise at 3 months, and full contact sports at 9-12 months, based on outcomes from the MOON cohort study of 2,459 patients.
Travel
Not citable:
Japan is an incredible destination with something for everyone, from ancient temples to modern cities.
Citable:
A 7-day Japan Rail Pass costs ¥50,000 ($333) and covers unlimited rides on all JR trains including most Shinkansen bullet trains between Tokyo, Kyoto, Osaka, and Hiroshima, making it cost-effective for any itinerary with at least one Tokyo-Kyoto round trip (¥27,000 without a pass).
Legal
Not citable:
There are many factors to consider when choosing the right business structure.
Citable:
An LLC in Wyoming offers the lowest formation costs among all U.S. states ($100 filing fee, $60 annual report) with no state income tax, making it the most cost-effective option for single-member LLCs with no physical Wyoming presence, though businesses with employees or physical operations should typically incorporate in the state where they operate to avoid foreign qualification fees.
You're seeing the pattern. The citeable versions aren't simpler. They're richer. More information, more structure, more useful.
Longer too. I'll get to that, I promise.
Combining it all #
Here's how all five things work together on one piece of text: utility-writing in practice. I'll use a real estate example, but the same analysis applies to anything.
Before (typical marketing copy):
Welcome to this fantastic property in one of Antwerp's most desirable neighborhoods! With its spacious layout and many original features, this home is perfect for a growing family. The property has been well-maintained and offers plenty of potential for those looking to add their personal touch. Don't miss this rare opportunity!
Every sentence fails every lens. No extractable core. No specifics. Unresolved references. No relationships. No citeable statements.
After:
This three-bedroom terraced house at Cogels-Osylei 12, Zurenborg (Antwerp) offers 165m² of living space across three floors, built in 1905 in the distinctive Zurenborg Art Nouveau style. The property at Cogels-Osylei 12 currently has an EPC score of 380 kWh/m² (energy label D), with an estimated renovation cost of €25,000-35,000 to reach energy label B through roof insulation and double glazing. Properties renovated to energy label B or higher in the Zurenborg conservation area have appreciated an average of 6.8% annually over the past five years, compared to 4.1% for unrenovated equivalents. Listed at €425,000, this Zurenborg property is priced 12% below the neighborhood average for three-bedroom homes, reflecting the energy renovation opportunity.
More words. More data. More complexity. But every sentence carries its own structure. Entities named ("the property at Cogels-Osylei 12" not "this home"). Relationships stated ("EPC score of 380 kWh/m², corresponding to energy label D"). Conditions preserved inline ("for properties with an EPC score above 400 kWh/m²").
No structured data markup needed. The language is the structure.
Same transformation, different industry. B2B SaaS:
Before:
Our innovative project management solution helps teams work better together. With powerful features and an intuitive interface, you'll wonder how you ever managed without it. Trusted by thousands of companies worldwide.
After:
Linear is a project management tool designed for software engineering teams of 10-200 people who use sprint-based workflows. Linear syncs bidirectionally with GitHub and GitLab, automatically linking pull requests to issues and moving issues to 'In Review' when a PR is opened. At $8 per user per month (billed annually), Linear costs 52% less than Jira Software Premium ($16/user/month) for teams that don't need Jira's portfolio planning features. The free plan supports up to 250 active issues per team workspace with no time limit.
The utility-writing transformation is the same across industries: generic marketing replaced with structured language. Entities named, relationships stated, conditions preserved, alternatives compared.
A beginners' trap: oversimplifying #
One important warning. "Optimizing for LLMs" by dumbing content down doesn't work.
Research tested a minimalist strategy (reducing product descriptions to single sentences) and it scored second-worst of 15 strategies tested, behind only a deliberately anti-factual storytelling control25. Let that sink in for a moment. Oversimplifying your content performs almost as badly as actively making stuff up.
"Battery: 18 hours" is easy to extract but dangerously incomplete. 18 hours doing what? Under what conditions? "Starts at $49/month" without stating what's included, what's limited, and what triggers the next tier is equally incomplete. "Recovery takes 6-8 weeks" without specifying which procedure, which patient population, and what counts as "recovery" is medically misleading and computationally useless.
Dense, specific, condition-preserving prose beats both verbose marketing copy and stripped-down data points. Add structure to your language. Don't strip your language down to structure.
This works both for LLMs AND Google #
I wrote about this in detail in The Shared Mechanism, but the short version: Google's passage ranking, AI Overviews, featured snippets, and third-party LLMs like ChatGPT all evaluate content at the passage level using similar retrieval infrastructure. A sentence that works for one works for all of them.
One thing worth adding here though. Doug Turnbull's work on semantic search points out that precise categorical language matters more than most people think26. Retrieval systems don't just measure similarity, they also need to match: deciding whether something should be included or excluded from results. And that's where generic language fails27.
"Handheld gaming PC in the portable console category" gives these systems more to work with than "gaming device." Same goes for "semi-automatic espresso machine" vs "coffee maker" and "anterior approach hip replacement" vs "hip surgery." The more precisely you name what something is, the better systems can match it to the right queries.
What I'm still figuring out: How to combine this with emotional persuasion (a.k.a. "writing for humans') #
Everything above focuses on the factual, structural side of content: entities, relationships, conditions, specifics. And I'm pretty confident about that part. But... it's boring and quite intensive to read, to be honest.
Content isn't just facts. It's also tone, emotion, persuasion, storytelling. And that's where I'm still searching.
The tension most people assume exists ("write for humans OR write for machines") is, I think, a false one. But it's not trivial to resolve either.
Here's what I've found useful so far. Dorron Shapow writes about the distinction between germane and extraneous cognitive load. Extraneous load is noise: friction that serves no purpose, that makes someone work harder without helping them understand anything better. That should go. But germane load (the kind that actually helps someone process what they're reading, that slows them down just enough to grasp something important) is not a bug. It's a feature.
I think that distinction maps directly to what I'm doing here. Structured language removes the extraneous stuff: the vague pronouns, the missing subjects, the stripped conditions. That's noise for humans and machines. But it keeps (and even strengthens) the germane stuff: the specifics, the conditions, the relationships, the context that helps someone actually make a decision.
A page that helps someone understand a complex decision is allowed to be harder to read than a landing page selling socks. And a system that gives personalised answers to nuanced questions needs exactly that kind of depth to cite you reliably.
So the question I keep running into is not "human vs machine" but: how do you write sentences that carry both emotional weight and factual structure? A property listing that makes you feel something about the neighborhood while also stating the price, the EPC score, and the subsidy conditions. A product page that tells a story about who this is for while naming the specs, the comparisons, and the trade-offs.
I've been testing this in my analysis: scoring content on both its factual extractability and its human readability, and looking for patterns in content that scores high on both. I don't have a neat conclusion yet. But I think this is where the real work is heading.
What I think the next step is: combining UX with utility-writing in microcopy #
The tension between emotional persuasion and structured language might be partly a design problem. Specific UI components (a hero section, a product card, a testimonial block, a CTA) each have their own job. And I think each of them can be designed and written in a way that does both: carries emotional weight for humans and structured information for machines.
That's what I'm currently working on. Taking common design components, rewriting the microcopy inside them according to the five criteria above, and showing what that looks like before and after. No conclusions yet, but that's the next article. You'll want to read it too, because it'll contain many examples too ;)
Two things you can do right now #
Remember the sentence test from the top of this article and the Bio Rewriter? If you haven't tried them yet, now's the time.
-
1.
Do the exercise from the top of this article: pick a sentence from your website and see if it survives on its own.
-
2.
Try the Bio-rewriter: paste your bio and get it scored on all 5 checks.
References #
- 1 HippoRAG (Gutierrez et al., NeurIPS 2024). Triple extraction uses open information extraction from passages, no predefined schema. [link] back
- 2 Dense X Retrieval (Chen et al., EMNLP 2024). Propositions defined as atomic, self-contained expressions of meaning: distinct, minimal, and self-contained. [link] back
- 3 Forrester, D. "The New Content Failure Mode: People Love It, Models Ignore It." DuaneForresterDecodes, Jan 25, 2026. "The Utility Gap is the simplest way to name the problem." [link] back
- 4 Forrester, ibid. "A retrieval plus generation system works differently. It retrieves candidates, it consumes them in chunks and it extracts signals that let it complete a task. back
- 5 Forrester, ibid. "A page can be excellent for a human and still be low-utility to a model. back
- 6 Kopp, O. "Ultimate guide for LLM readability optimization and better chunk relevance." Aufgesang / kopp-online-marketing.com. RAG process model: Information Retrieval, Source Qualification (E-E-A-T filters), Chunk Extraction, Context Provision, Generation. [link] back
- 7 Kopp, ibid. "Even if your document is not the most relevant in the source set, you can still be cited if your chunks are more relevant or your structure can be processed better than competitors. back
- 8 Petrovic, D. "How big are Google's grounding chunks?" DEJAN, December 2025. 7,060 queries, 883,262 snippets. Median total budget: 1,929 words (p25: 1,546; p75: 2,325; p95: 2,798). [link] back
- 9 Petrovic, ibid. "Rank Determines Your Share" table: #1 source: 531 words (28%), #5: 266 words (13%). back
- 10 Petrovic, ibid. Per-Source Selection: median 377 words / 2,427 characters. back
- 11 Petrovic, ibid. Coverage: pages under 5K chars: 66%; 5-10K: 42%; 10-20K: 25%; 20K+: 12%. back
- 12 Petrovic, ibid. "Adding more content dilutes your coverage percentage without increasing what gets selected. back
- 13 Petrovic, ibid. Key Takeaway and concluding line: "density beats length. back
- 14 "Lost in the Middle: How Language Models Use Long Contexts" (Liu et al., 2023), referenced in Forrester's Utility Gap article: "model performance can degrade sharply based on where relevant information appears in the context. Results often look best when the relevant information is near the beginning or end of the input, and worse when it sits in the middle." back
- 15 Forrester, ibid. "Treat mid-page content as fragile. If the most important part of your answer sits in the middle, promote it or repeat it in a tighter form near the beginning." back
- 16 E-GEO (Bagga et al., 2025). 7,000+ product queries, 15 rewriting strategies. Optimized prompts converged on: user intent, competitiveness, reviews/ratings, factuality. Tested in e-commerce; cross-domain generalization untested. [link] back
- 17 Forrester, D. Product Rewrite Guide for AI Platform Optimization. DuaneForresterDecodes. "Write one sentence that answers four questions cleanly: What is it? Who is it for? What job does it do? Under what constraint or context does it win?" [link] back
- 18 Forrester, Product Rewrite Guide, ibid. "When your opening line is a slogan, the system has to infer what the product is actually for. Inference introduces uncertainty. Uncertainty reduces selection." back
- 19 Dense X Retrieval, ibid. Proposition-level outperforms passage-level across all four tested retrievers (SimCSE, Contriever, DPR, GTR). For a fixed 100-200 word budget: approximately 10 propositions fit vs approximately 5 sentences vs approximately 2 passages. back
- 20 Dense X Retrieval, ibid. "Not Stand-alone" error rate: 4.9% (GPT-4), 3.1% (Propositionizer). "The main issue is occasional failure to be fully self-contained (missing coreference resolution)." back
- 21 HippoRAG, ibid. "The triple extraction uses open information extraction (no predefined schema)." Input: passage. Output: (subject, predicate, object) triples. back
- 22 HippoRAG knowledge file, "Implications" section: "content written in clear natural language with explicit subject-verb-object structures gets extracted more accurately than bullet point lists without verbs, tables without relational context, or fragment sentences that require inference." Note: interpretive analysis of HippoRAG's mechanism. back
- 23 HippoRAG, ibid. "If any link is missing, the chain breaks." HippoRAG outperforms state-of-the-art by up to 20% on multi-hop QA benchmarks. back
- 24 Forrester, "The New Content Failure Mode." "Write anchorable statements. Models often assemble answers from sentences that look like stable claims. Clear definitions, explicit constraints, and direct cause-and-effect phrasing increase usability." back
- 25 E-GEO, ibid., Table 2: Minimalist prompt ("Reduce to a single sentence") scored -1.66, worst non-narrative strategy. Storytelling (-4.03) was worse but is explicitly a "negative control." back
- 26 Turnbull, D. "Semantic Search Without Embeddings." softwaredoug.com, January 8, 2026. "One pain point comes up right away with embeddings: lack of matching." [link] back
- 27 Turnbull, ibid. "Importantly, this becomes just ONE component of the ranking/filtering." back
- A (very) small but useful exercise to get things going
- The main takeaway of this article: add structure to language
- Why this matters now, and should have mattered years ago already
- A quick word on what this framework is NOT: guaranteed citations
- This framework is built on mechanisms; not heuristics
- See it in action: the bio-rewriter
- My 5-point usefulness check, a.k.a. the Eikhart Language Utility Framework
- Combining it all
- A beginners' trap: oversimplifying
- This works both for LLMs AND Google
- What I'm still figuring out: How to combine this with emotional persuasion (a.k.a. "writing for humans')
- What I think the next step is: combining UX with utility-writing in microcopy
- Two things you can do right now
- References
Ramon Eijkemans
Eikhart - Mad Scientist