

Ramon Eijkemans
Eikhart - Mad Scientist
Google Sheets redirect chain checker
Redirect-chains are something you need to analyse a lot when dealing with migrations, redirects, or broken link building: it's a thing.
With this post I am following up on my earlier post about more advanced web scraping with Google Sheets. This time around I present to you: a dedicated bulk redirect-chain checker.
No need to install anything. Just copy & paste the code in the right place (follow the instructions below), call the custom function =scraper(url) and off you go.
You can easily use it for a lot of URLs: 1k - 5k maybe even (until Google Sheets starts complaining about Too Many Requests).
Step 1: Add the Cheerio library to your sheet #
Did you know you can load external libraries into Google Apps and so use their goodness? For this, I've used Cheerio, which basically mimics jQuery's element selection easyness.
-
1.
In the Google Sheet you want to use this script with, go to
Extensions>Apps Script -
2.
Now you’re in the In Apps Script interface. Go to
Librariesin the sidebar to the left, and click the+button -
3.
Copypaste the following library ID:
1ReeQ6WO8kKNxoaA_O0XEQ589cIrRvEBA9qcWpNqdOP17i47u6N9M5Xh0 -
4.
Click
Lookup, select the highest number from the list, and clickAdd
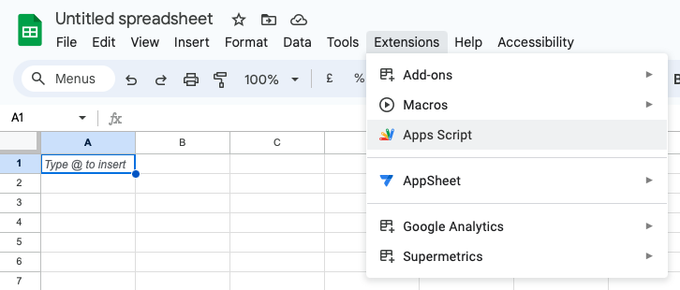
Go to Extensions > Apps Script
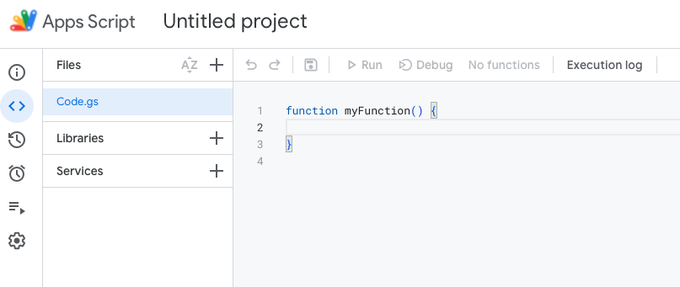
Delete the placeholder code, and optionally rename the script and the project (I renamed them to scraper.gs and 'Eikhart - Redirects', respectively.)
Congrats! Now you’ve added the scraping power of Cheerio to your Apps Script! This will enable you to use css selectors instead of xpath, which is way easier (thank me later).
Also, for those of you familiar with jQuery: it uses a familiar syntax for selecting stuff ;)
Step 2: copy paste this Apps Script #
-
-
Still Apps Script interface, go to
Filesin the sidebar to the left, and click theCode.gsmenu item. -
-
Select all code in the field to the right, and delete the
function myFunction() {}example code -
-
Now replace it with the following code:
/**
* Output scraper results in Google Sheet-compatible rows
* Source & explanation: https://eikhart.com/possibly-useful-article-about/google-sheets-redirect-chain-checker
*
* @param {string} url or empty
* @return {array} Google Sheets compatible
* @customfunction
*/
function scraper(url) {
let result = [];
/**
* Step 1.
* Config and defaults: we'll declare some objects with a key:value paiitem. The sequence of the objects will be the sequence of columns we'll see in the Sheet
* - The key is the name of the column header
* - The value will be whatever is returned by the scraper
* We'll define the names and the default values here. The scraper will then execute, and overwrite the values with whatever it finds (otherwise, the default value will be returned to Google Sheets)
*/
let http = {} // the header object. The first one we'll output
http.requestedUrl = url; // the url in the Google Sheets cell that references scraper()
http.requestedUrlStatus = false; // to be determined!
http.loadedUrl = false;
http.loadedUrlStatus = false;
http.fullChain = []; // for now an empty string
http.allLocations = []; // for now an empty array. If we find redirects, then their urls will be collected here
http.allStatusCodes = []; // for now an empty array. Should become at least one status code
http.chainLength = 0; // should become > 0 if (a) redirect(s) is encountered
http.httpxrobots = [];
let html = {} // the meta tags object. Second group of outputs
html.title = false;
html.robots = false;
html.canonical = false;
html.canonicalSameAsLoadedUrl = null; // empty string, only relevant if there are both a canonical and a loadedUrl
let logs = {}
logs.remarks = [];
/**
* Step 2.
* Check if any url was given to the scraper() function from Google Sheets
* If not, parse the config object and only return the keys: they will output all column names
*/
// no (valid) url given? output column headers, by concat()-ing all object keys
if(!url) {
result.push(
Object.keys(http) // http header column headings
.concat( Object.keys(html) ) // html column headings
.concat( Object.keys(logs) ) // logs column headings
);
}
/**
* Step 3.
* A valid URL was given to the scraper, so now we can actually start to scrape
*/
else {
// make the request and capture response - array containing 1+ object(s) with scraped http headers & html per url
let output = fetch(http.requestedUrl,http.chainLength);
output = output.reverse(); // there is probably a good reason why the response if flipped upside down. I don't know why nor care though. Just reverse it
/**
* Step 4.
* The magic is actually done in the fetch() function (see below).
* Here, we're just busy with collecting the output from the fetch() function
*/
// start looping the results, and prep output
for(let i = 0; i < output.length; i++) {
let l = output[i].call;
/**
* Step 5.
* The response is an array with information for every single URL it finds (might be more than 1 when there's redirects involved)
* We loop the array, and for every URL we add the information we scraped to the designated config placeholders we declared earlier
*/
if(l) {
// populate arrays
let location = '';
if(l.location) {
location = ', note: to a relative location: ' + l.location + '';
}
http.fullChain.push(l.url + ' => ' + l.status + location); // fullChain string array
http.allStatusCodes.push(l.status); // all status codes array
if(l.status > 300 && l.status < 399) {
http.chainLength = http.chainLength + 1;
}
http.allLocations.push(l.url); // all locations array
http.httpxrobots.push(l.httpxrobots);
if(l.html) {
html.title = l.html('title').first().text() || false; // html title tag text value
html.robots = l.html('meta[name=robots]').attr('content') || false; // robots
html.canonical = l.html('link[rel=canonical]').attr('href') || false; // canonical
html.canonicalSameAsLoadedUrl = (html.canonical === l.url); // the same?
}
if(l.remarks) {
logs.remarks.push(l.remarks);
}
}
}
/**
* Step 6.
* The individual values per URL were collected and saved in step 5. Now we're converting that data into flattened strings. So that we can actually output it in a Google Sheets cell.
*/
// http header
http.requestedUrlStatus = http.allStatusCodes[0];
http.loadedUrl = http.allLocations[http.allLocations.length -1]; // the last url from the allLocations array
http.loadedUrlStatus = http.allStatusCodes[http.allStatusCodes.length -1]; // and its status code
if(http.loadedUrlStatus > 399) {
logs.remarks.push('URL error: final loaded URL results in an error, statuscode: ' + http.loadedUrlStatus);
}
// Check: differences in redirect chain status codes?
let statusesWithoutLast = http.allStatusCodes.slice(0, -1);
let distincts = statusesWithoutLast.filter( getDistincts );
if(distincts.length > 1) {
logs.remarks.push('Redirect-chain error: Different status codes found inside chain: ' + statusesWithoutLast.join(" > "));
}
// Overwrite the declared object/variables with what we've found. Make sure they're flattened!
http.httpxrobots = http.httpxrobots.join('\n');
http.allLocations = http.allLocations.join("\n"); // allLocations string
http.allStatusCodes = http.allStatusCodes.join("\n > "); // all status codes in a single string
http.fullChain = http.fullChain.join("\n"); // the complete locations and status codes collection in a single string
// Combine all logs into a single string
logs.remarks = logs.remarks.join("\n").replace("\n\n","\n");
/**
* Step 7.
* The different groups of information (http headers and reports about it, some html tags and the logs)
* are combined into a single multidimensional output array, so that Google Sheets understands it
*/
// concatenate them all into a single result object
result.push(
Object.values(http) // heading column headings
.concat( Object.values(html) ) // meta column headings
.concat( Object.values(logs) ) // logs column headings
);
}
// wrap it up
return result;
}
/**
* Helper functions
*/
/**
* fetch a given URL, and return response
*
* @param {url}
* @param {int} (chain length counter)
* @return {object}
*/
function fetch(url,chainLength) {
let result = []; // placeholder array to push new objects (rows) into
let row = {}; // placeholder object for current url row
let logs = [];
const chainLimit = 10;
const chainWarning = 3;
try {
// config request
let options = {
'muteHttpExceptions': true,
'followRedirects': false, // we'll loop them manually
};
// uncomment if you want to enter an area that is protected with basic auth
/**
* const basicAuthUser = "user";
* const basicAuthPass = "pass";
* options.headers = {
* "Authorization": "Basic " + Utilities.base64Encode(basicAuthUser + ":" + basicAuthPass, Utilities.Charset.UTF_8),
* }
*/
// uncomment if you want to enter an area that is protected with an authorization token
/**
* const token = "XXXXXXXXXXXXXXXXXXXXX";
* options.contentType: 'application/json',
* options.headers = {
* "Authorization" : token
* }
*/
// uncomment if you just need to send custom headers. I'll give you an example
/**
* options.headers = {
* "custom_header_key": "a-key",
* "custom_header_secret": "a-secret"
* }
*/
// go get it
if(url) {
let response = UrlFetchApp.fetch(url, options);
// http info
row.url = url; // requested url
row.status = response.getResponseCode(); // status code
row.httpxrobots = response.getHeaders()['X-Robots-Tag']; // xrobots
// follow redirect if a 'location' is given
if(response.getHeaders()['Location']) {
let l = response.getHeaders()['Location'];
// Relative url? Parse it and make it a full URL
if(l.lastIndexOf('/', 0) === 0) {
row.location = l; // add it as a special remarks in the allLocations array
// correct if neccesary
let correctedLocation = parse_url(url)['protocol'] + '://' + parse_url(url)['host'] + l;
l = correctedLocation;
}
// at warning level? show the warning, but continue
if(chainLength === chainWarning) {
logs.push("Result rows warning length ("+ chainWarning +") reached. Continuing until we've reached the limit of " + chainLimit);
}
// at limit?
if (chainLength === chainLimit) {
logs.push("Result rows limit ("+ chainLimit +") reached. Stopping crawling more parts of this chain");
}
if(chainLength < chainLimit) {
result = fetch(l,chainLength + 1);
}
}
// no location? Then use Cheerio for the returned content (usually HTML)
else {
if(response.getContentText() ) {
row.html = Cheerio.load(response.getContentText() );
}
}
}
row.remarks = logs.join("\n");
// result
result.push({ call: row });
}
catch (error) {
result.push(error.toString());
}
finally {
return result;
}
}
// extract distinct values from array (de-duplicate)
/*
Usage:
let distinct = codes.filter( getDistincts );
if(distinct.length > 1) {
log.push('Different status codes');
}
*/
function getDistincts(value, index, self) {
return self.indexOf(value) === index;
}
/**
* Parse URL return components, or the whole URL as an associative array
*
* @param {url} valid url please
* @return result (array values)
*
* Examples:
* let url_parts = parse_url(urls); *
* let protocol = url_parts['protocol'];
* let host = url_parts['host'];
* let port = url_parts['port'];
* let path = url_parts['path'];
* let query = url_parts['query'];
* let fragment = url_parts['fragment'];
*/
function parse_url(url) {
let match = url.match(/^(http|https|ftp)?(?:[\:\/]*)([a-z0-9\.-]*)(?:\:([0-9]+))?(\/[^?#]*)?(?:\?([^#]*))?(?:#(.*))?$/i);
let ret = new Object();
ret['protocol'] = '';
ret['host'] = match[2];
ret['port'] = '';
ret['path'] = '';
ret['query'] = '';
ret['fragment'] = '';
if (match[1]) { ret['protocol'] = match[1]; }
if (match[3]) { ret['port'] = match[3]; }
if (match[4]) { ret['path'] = match[4]; }
if (match[5]) { ret['query'] = match[5]; }
if (match[6]) { ret['fragment'] = match[6]; }
return ret;
}That should look something like this in the interface:
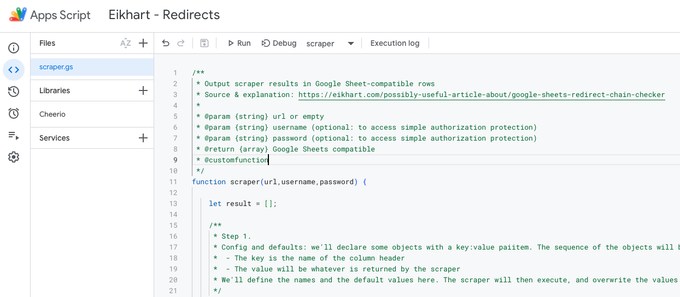
And this is what you should see after you've added Cheerio and copy pasted this script
That's it. Now you can give this function a URL, and it will return all kinds of stuff about redirects, redirect chains, locations, status codes, and even canonicals for you. I'll show you how.
Step 3: use it #
There are three ways to use it:
-
1.
Use
=scraper()to only output column headings -
2.
Use
=scraper(url)to output everything the tool finds for that given URL -
3.
Use
=scraper(url,username,password)to output everything the tool finds for that given URL, when that URL is hidden behind a simple authentication layer. Use this to debug redirects on an acceptation environment!
Optional config: crawl password protected areas #
When you're working in a professional environment, the website should have an acceptation area, and you as an SEO should have access to it. This is perfect to test redirects before they go live!
Or: the website is protected with something like Cloudflare and it's blocking you unless you send a specific header with each request. I got you covered!
The script contains a few common ways to deal with authorization. I have however, commented them out, so you need to uncomment and modify it with your specific credentials to make it work.
Look for this part in the code, and adjust accordingly:
// uncomment if you want to enter an area that is protected with basic auth
/**
* const basicAuthUser = "user";
* const basicAuthPass = "pass";
* options.headers = {
* "Authorization": "Basic " + Utilities.base64Encode(basicAuthUser + ":" + basicAuthPass, Utilities.Charset.UTF_8),
* }
*/
// uncomment if you want to enter an area that is protected with an authorization token
/**
* const token = "XXXXXXXXXXXXXXXXXXXXX";
* options.contentType: 'application/json',
* options.headers = {
* "Authorization" : token
* }
*/
// uncomment if you just need to send custom headers. I'll give you an example
/**
* options.headers = {
* "custom_header_key": "a-key",
* "custom_header_secret": "a-secret"
* }
*/That's it #
I hope you'll find it useful. I've been using this script for quite some years now for my own projects but never really shared it with the community. Long overdue!
Ramon Eijkemans
Eikhart - Mad Scientist